robots.txtとは?
robots.txtとは検索エンジンのクローラーの巡回を制御するファイルです。クローラーが不必要なコンテンツへアクセスできないようにrobots.txtで制限する事で、サーバーの負荷を軽減し、巡回の効率化を図る事ができます。検索結果に表示されないようにするには、robots.txtではなくnoindexを使用します。
2023年の12月の時点でのGoogleの発言では、Google は Robots.txt について毎日 40 億のホスト名をチェックしているようです。

robots.txtは1994年にMartijn Koster氏によって考案されました。特定のクローラをブロックする事の他、検索エンジン向けにxmlサイトマップファイルの位置を指定する事もできます。
通常は、robots.txtというファイルを作成し、クローラーを制御する記述を含めてウェブサイトのトップディレクトリの直下にFTPでアップロードします。
robots.txtはどのような場合に必要か?
ウェブサイトの規模が大きく、クローラーがサーバーのパフォーマンスに大きく影響している場合には、robots.txtでクロールを制御します。それとともにクロール効率化の為にXMLサイトマップ、rssフィードを設定しておくと良いでしょう。
robots.txtはクロールをコントロールする目的のみに使用します。検索結果に表示させない目的では使用する事ができません。その場合はnoindexやベーシック認証を使用しましょう。
クロールを制限するページ
例えば、以下の用途が考えられます。
CMSを使用している場合はCMSのログインページ
検索エンジンに巡回させる意味がありませんので、ブロックしても良いでしょう。
会員向けのコンテンツ
一般的にはベーシック認証などを使用して第三者のアクセス自体を制限します。
ショッピングカート内の決済プロセス
ECサイトの場合は、一般的には商品ページから購入ボタンをクリックすると決済画面に遷移します。(この決済画面のURLは訪問者ごとに異なり、動的に生成されると思います。)
カート内のページのように動的に生成されるURLは検索ユーザーにとっては価値の無いページです。
規模が大きなサイトになるとクローラーの巡回効率が落ち、サーバーへの負荷も高くなっていく場合があります。
クローラーは毎日あなたのウェブサイトの全ページを巡回しているわけではなく、サイトの規模や更新頻度などの要素に応じてクロールの際にダウンロードするサイズを割り当てています。不要なページにクローラーが巡回する事でサーバーへの負荷が増す為、このような場合においてrobots.txtを使用すると良いでしょう。
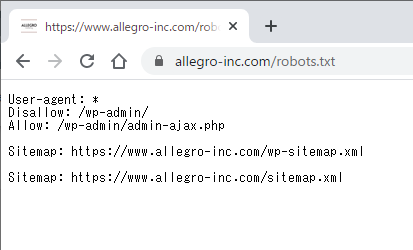
負荷を増大させている原因がGoogleだけとは限りませんので、海外のクローラーやアーカイバーなども制御しておく場合もあります。(ia_archiverなど。)
robots.txtの記述方法
User-agent: *
Disallow: /wp-admin/
Sitemap: http://www.example.com/sitemap.xml
WordPressの場合は、以上のように設定されている事が多いと思います。
これは、全てのクローラーに対して、/wp-admin/へのアクセスをブロックする為の記述です。
User-agent
User-agentは、ユーザーエージェントと読みます。ここに対象の検索エンジンのクローラーを指定します。
最近ではGoogle-ExtendedなどAI学習用のクローラーも発表されています。AIによって自身のコンテンツが活用されることを防ぐために、ブロックするといった使い方は今後増えてくるかもしれません。
各検索エンジンクローラーのユーザーエージェントは、以下のページから確認できます。
http://www.robotstxt.org/db.html
Disallow
Disallowは、指定したURLへの巡回をブロックします。
ウェブサイト公開前であれば、「/」スラッシュでウェブサイト全体の巡回をブロックします。
特定のディレクトリ内を全てブロックする場合は、「/sample/」のように記述します。(/sample/ディレクトリ内を全てブロックする記述です。)
「/privacy.php」のように特定のページ単位でも指定ができます。
以下の記述は ChatGPT のプラグインで使用されるユーザーエージェントをブロックする記述です。ChatGPT プラグインのみに作用するので、プラグインを使ってページの情報にアクセスされることを防ぎます。(ウェブサイトのクロールでは、このユーザーエージェントを使用していないようです。)
User-agent: ChatGPT-User
https://platform.openai.com/docs/plugins/bot
Disallow: /
他にもAllowという記述をする事もあります。これは、Disallowでブロックされたディレクトリ内の特定の子ディレクトリのURLのクロールのみを許可する場合に記述します。
robots.txtで特定のディレクトリをDisallowに設定しても、すぐには検索結果には影響しません。
Googleがrobots.txtの変更を認識するまでの時間に加えて、その後URL単位で再処理が開始されます。
If I disallow: / today, and Google sees it tomorrow, it doesn’t change all of the URLs into robotted tomorrow, it only starts doing that on a per-URL basis then.
John Mueller氏のコメント
Sitemap:
XMLサイトマップの場所をクローラーに伝えます。
Googleに関しては、Search ConsoleでXMLサイトマップを登録していれば不要ですが、他の検索エンジンもあるので記述した方が良いでしょう。
コメントアウト
コメントアウトは、#を使用します。
# 2021/4/7 追加
User-agent: *
Disallow: /wp-admin/
Sitemap: http://www.example.com/sitemap.xml
その他:noindex、nofollow、crawl-delay
公式の方法ではありませんが、robots.txtに「noindex」、「nofollow」、「crawl-delay」を記述して一部のクローラーに処理を伝える事ができていましたが、2019年11月以降はGoogleボットではサポートされません。
robots.txtの形式、アップロード場所
robots.txtというファイル名で保存し、ウェブサイトのディレクトリトップ(第一階層)にアップロードします。
サブドメインでもトップディレクトリにアップロードすれば認識されるようです。
但し、サブディレクトリにアップロードしても検出されないようです。
ファイル形式
Robots.txt のファイル形式は以下の通りとされています。
予期されるファイル形式は、UTF-8 でエンコードされた書式なしテキストです。このファイルは、CR、CR/LF、または LF で区切られたレコード(行)で構成されます。
Googleの場合はtxt形式以外にHTMLページでも正しく記述されていれば問題無いようです。
ファイルサイズの上限
最後にrobots.txtのエラーが無いか確認
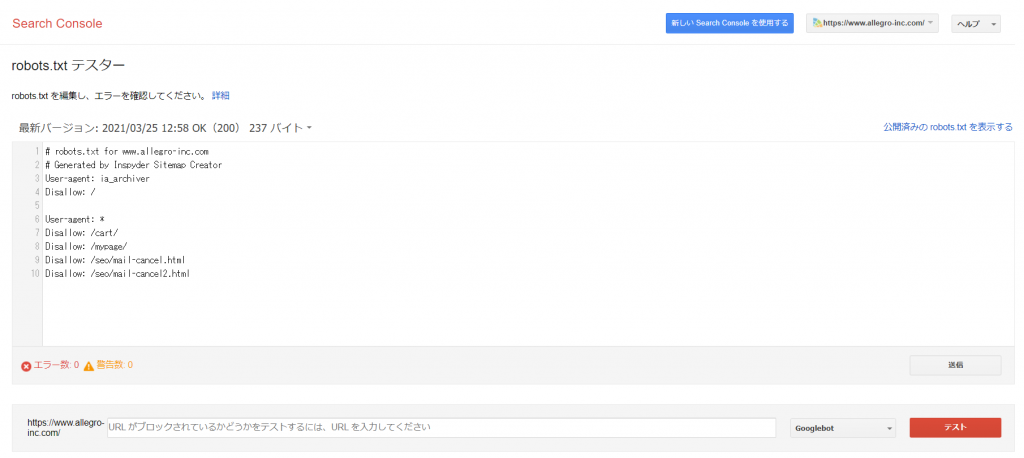
アップロード後には必ずSearch Consoleのrobots.txtテスターでエラーが無いか確認しましょう。
該当するプロパティを選択して「robots.txtテスター」が表示されたら、特定のURLを入力して「テスト」ボタンをクリックします。
robots.txtの注意点
robots.txtを使用する場合には、いくつか注意点があります。
連続するリダイレクトは10回まで処理できる
それ以上のリダイレクトはSearch Consoleでエラーとして扱われるようです。
設置したrobots.txtに対して4XXレスポンスを返した場合(429を除く)
robots.txtにアクセスした際に429を除いた4XX (403や404) ステータスコードを返している場合は、Googleはrobots.txtのルールを無視するそうです。(429 ステータスコードは、指定された時間内に多くのリクエストを送信したことを示します。)
PSA from my inbox: if you serve your robotstxt with a 403 HTTP status code, all rules in the file will be ignored by Googlebot. Client errors (4xx, except 429) mean unavailable robotstxt, as in, a 404 and a 403 are equivalent in this case.
Gary Illyes氏のコメント
5XXレスポンスの場合の処理
Googleは一時的な処理として、サイトへのアクセスが完全に許可されていないものとして認識します。
30日間の間robots.txtに5xxレスポンスでアクセスできなかった場合は、それ以前のキャッシュされているrobots.txtファイルが使用されます。キャッシュされていない場合は、クロールに対する制限は無いものとして処理されます。
500/503レスポンスの場合の処理
robots.txtファイルにアクセスした際に、一定期間を過ぎて500/503HTTPステータスコードを返したままの状態にすると、Googlebotがサイトのその他の部分にアクセスできる状態であっても、検索結果から該当サイトが削除されるようです。長期間のネットワークタイムアウトの場合も同様の処理となるようです。
A robots.txt file that returns a 500/503 HTTP status code for an extended period of time will remove your site from search results, even if the rest of the site is accessible to Googlebot. Same goes for network timeouts.
Gary Illyesの発言
サーバーエラーとして処理
リクエストの失敗や不完全なデータの場合は、サーバーエラーとして処理されます。
robots.txtの強制力
robots.txtはGoogleなどの主要な検索エンジンは記述通り指示に従うようですが、中には無視するクローラーもあるようです。完全にブロックするには、ベーシック認証を設定した方がよいかもしれません。
外部参照リンクから巡回されたページはブロックされない可能性も
クローラーが他のウェブサイトからの参照リンクを辿ってrobots.txtでブロックされているあなたのページに巡回してしまった場合は、インデックスされてしまう可能性はあるようです。ベーシック認証や、noindexメタタグなどを使用してブロックしておくと良いでしょう。
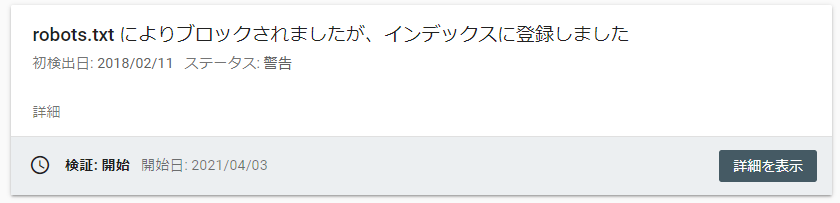
ページの構成要素の一部として利用されるURLはブロックされない
クロールを許可しているAというページと、Aというページをレンダリングする際に必要なBというURL(htmlやphpファイルを含む)があった場合、BのURLをrobots.txtでブロックしていてもレンダリングに必要なリソースの為、Googleが強制的にクロールする事はあります。
このようなケースではSearch Consoleのカバレッジレポートで「robots.txtによりブロックされましたが、インデックスに登録しました」と表示されます。
Googleがレンダリングに必要なリソースはrobots.txtでブロックしないようにしましょう。
インデックスの削除目的でrobots.txtを使用しない
サイト全体のインデックス削除を目的にrobots.txtを使用したとしても、それらが削除されるまで多くの時間がかかり、場合によってはトップページは残ってしまう可能性があるそうです。
Even if you disallowed all crawling, it would take quite some time for the whole site to drop out, and likely things like the homepage woud remain indexed. What you’ve posted here is imo irrelevant. My guess is you did something totally unrelated, like submit a site-removal request for http:// (which removes all versions, as documented).
John Muller氏のコメント
このような場合は、古いコンテンツの削除ツールを使用する方が適切です。
noindexとrobots.txtでよくある誤った設定
既存のインデックスされているページを検索エンジンに表示させないようにメタでnoindexを設定し、robots.txtでそのページへのクロールもブロックしてしまうと、いつまでたっても検索結果に表示されたままになってしまうようです。
@suzukik あるページが既にインデックスされている場合、それをインデックスされないようにするために robots.txt でクロールをブロックしてしまい、結果として noindex が検索エンジンに認識されないままになってしまう、というのはしばしば見られる誤りなので、
— Kazushi Nagayama 🗿 長山一石 (@KazushiNagayama) October 15, 2015
robots.txtの設定とnoindexの設定は誤解が多い為、正しい理解が必要です。
robots.txtの設定ミスは致命的
サイト公開直後に、Googleが巡回する前に誤ってウェブサイト全体をブロックしてしまうと、検索結果上で多くのページが表示されなくなります。
誤った記述が無いか確認し、robots.txtテスターでのチェックも必ず行いましょう。
JavaScriptはブロックしない方が良い
クローラーの巡回効率ばかり気にしてしまうと、不要だと思うものを全てブロックしてしまいたくなりますが、cssやjavascriptはブロックしないように注意しましょう。
2014年5月23日にGoogleのJavaScriptの処理能力が向上した事をウェブマスター向け公式ブログで発言しています。Googleは通常のユーザーと同様にウェブページをレンダリングして、内容を判別します。
JavaScript内のリンクも評価される?
John Mueller氏のTwitterによると、JavaScriptリンクも他のリンクと同様にページランクを渡すようです。
右クリックやコンテンツ選択の禁止はSEOに悪影響?
ユーザー目線で考えると、右クリックやコンテンツ選択の禁止は使いにくいページではありますが、John Mueller氏のコメントによるとSEOには影響しないようです。
重複コンテンツに対してはrobots.txtは使用しない
robots.txtを重複コンテンツ対策で設置する事はGoogleのJohn Mueller氏もすすめていません。
Googleは重複コンテンツによる分散したコンテンツの評価を一つにまとめる仕組みがあります。
robots.txtを使用してブロックしてしまうと、ブロックされた重複コンテンツの評価を捨ててしまう事にもなるので、逆に評価が薄まってしまうかもしれません。
robots.txtを使用するのではなく、301リダイレクトやcanonical属性を使用するという方法が正しい対処方法となります。
robots.txtを頻繁に更新しても効果なし
- robots.txtはGoogleに24時間キャッシュされるため、1日に何度も更新しても反映されません。
- 「朝はクロールを止め、昼は再開」という更新を繰り返しても、Googleは最新状態を即座に取得しません。
- 代わりに「503(Service Unavailable)」や「429(Too Many Requests)」といったHTTPステータスを返す方法が推奨されています。これらのステータスはGooglebotに「クロールを一時停止すべき」と認識させるため、サーバー負荷調整に有用です。https://bsky.app/profile/johnmu.com/post/3lfud4v4lf22l
robots.txtで自身のrobots.txtをブロックするとどうなるか?
特にGoogleが行うrobots.txtの処理には影響を与えないようです。通常に処理されます。
もしあなたのrobots.txtを外部のウェブサイトがリンクしていて、万が一インデックスされてしまっていた場合には、そのrobots.txtはインデックスされず、検索結果にも表示されません。(インデックスさせる必要はそもそもありませんが。。)
robots.txtは基本的にはインデックスされませんが、外部からそのファイルへのリンクがあって、中身が記述してある場合には、インデックスされる事もあったようです。このようなケースで、もしインデックスからrobots.txtファイルを削除したい場合は、URL削除ツールを使うか、X-Robots-Tag HTTP ヘッダーでnoindexを指定するかどちらかの方法を取る事ができます。(ですが、放置しても良いとは思います。)
このツールを使うと、90日の間、検索結果からSearch Consoleで所有権を持つサイトのURLを非表示にする事ができます。一定期間を過ぎると再び検索結果に表示されます。
このツールでURLを非表示にしても、Googleのクロールやインデックスをブロックする事にはなりません。
robots.txtやcanonical、noindexなどは誤って設定すると検索結果での表示や順位に影響を与えてしまいます。
SE RankingのサイトSEO検査機能では、ウェブサイト内のページを巡回し、robots.txtの設定を含め、SEOの問題点を自動的に検出してくれます。
以下の方法で「クロール」や「インデックス」に影響する項目をチェックする事ができます。
SE Rankingの無料トライアルアカウント作成ページで自身のアカウントを作成しましょう。クレジットカード登録不要で2週間無料で利用できます。
以下の手順に沿って、チェック対象のウェブサイトに関するプロジェクトを作成しましょう。プロジェクトを作成してしばらくすると、サイトSEO検査が完了します。
左側メニューの「サイトSEO検査」のサブセクションの「問題点レポート」クリックして確認しましょう。
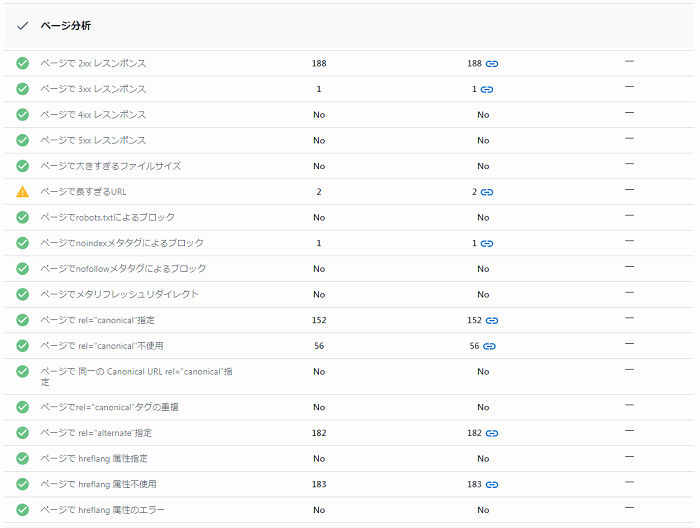
「クロール」セクションをクリックし、セクション内に問題点が無いか確認しましょう。問題点の項目をクリックすると改善方法のガイドが表示され、ページ列の数値をクリックすると問題が発生しているページも確認する事ができます。
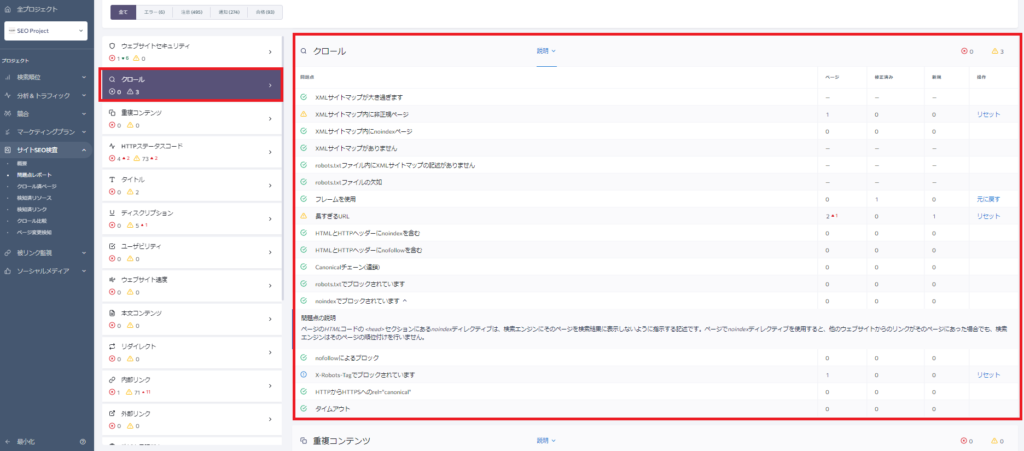
ベーシック認証でアクセスする検証環境のウェブサイトにも対応している為、リニューアルや新規サイト公開前のウェブサイトの品質チェックにも利用できます。