SEOで最も基本であり、必ず行わなければならない事を上げるとすると、少なくともウェブサイトのページをきちんとGoogleボットがクロールできるように設計しておく事です。
なぜならいくら素晴らしいコンテンツを作ってもGoogleがクロール・インデックスできなければ検索結果には表示されないからです。
クローラーとは?
一般的にGoogleなどの検索エンジンが使用する巡回ロボット(Googlebot)をクローラーと呼び、インターネット上のウェブページを巡回します。ページ上で検知したリンクやサイトマップファイルからクロール対象のリンクのリストを抽出し、新たなページを探します。クロールした後に、検索ユーザーに検索結果を提供するためにはインデックス処理を行います。
インデックスとは?
インデックスは、検索ユーザーのキーワードの関連性にふさわしいものを表示させる為にクロールしたページをデータベースに登録し利用できるようにする事を指します。またGoogleは取得したページなどの情報を一時的にキャッシュとして保存することもあります。
キャッシュとは?
キャッシュ(cache)とは、Googleが取得したページをサーバー内に保存することを意味します。Googleでは2024年1月の時点でキャッシュリンクは廃止されたことがわかっています。
MicrosoftはBing検索におけるキャッシュリンク(cache link)およびキャッシュ演算子(cache:)のサポートを正式に終了したことを2024年12月12日に発表しました。これは、Googleが同様の機能を廃止した後の動きであり、数か月にわたるテスト期間を経ての決定です。
Googleの「キャッシュ」機能は正式に廃止されました。もともとはページが正常に読み込めなかった時代のための機能でしたが、現在ではその必要性が薄れたためです。Google Search ConsoleのURL検査ツールを使えば、自分のページをGoogleがどう見ているかは確認できます。「cache:」検索演算子も使えなくなります。
Googleボット(Googlebot)とは?
Googleボットとは、インターネット上のウェブサイトの情報を収集する為にGoogleが使用しているウェブクローラーの総称です。
2019年5月のGoogleのアナウンスによると、今後は最新のChromeをベースにウェブページをレンダリングできるようになり、最新のウェブプラットフォームをサポートするようになります。
Googleは世界中のウェブサイトの情報を集めようとしてクロールしています。
GoogleBotは、サイト間のリンクを辿ったりウェブマスターからの通知によってウェブサイトを巡回していますが、ウェブサイト内の全てのコンテンツを確実にクロールするわけではありません。
ほとんどのケースでは気にする必要がありませんが、GoogleBotはウェブサイトの状態や、必要性を考慮してウェブサイトごとにリソースを割り当てて(一般的にはクロールバジェットと呼ばれます)クロールします。
クロールバジェットとは?
クロールバジェットとは、Googleでは「クロールの必要性(クロールディマンド)があり、かつ Googlebot がクロール可能な URL の数(クロールレート)」と定義されています。
なお、クロールバジェット自体はランキングファクターではありません。多く割り当てられているからといって、特に順位には影響はないようです。また、新しいウェブサイトに関しては大小の規模に関わらず、一定の初期値がクロールバジェットに割り当てられます。
クロールバジェットはホストネーム単位で割り当てられていることがGoogleの発言からわかります。同じドメイン内であっても、個々のサブドメインは独自のクロールレートやリミット(上限)が設けられているようです。
クロールバジェットを管理すべき対象者
クロールバジェットの管理に関しては、上級者向けの施策となります。主に以下のようなケースでクロール管理が必要となります(それ以外のケースではそれ程気にする必要はありません)。
- 大規模なサイト(100 万ページ以上)で、コンテンツの更新頻度が中程度(1 週間に 1 回)の場合
- 中規模以上のサイト(10,000 ページ以上)で、(日常的に)コンテンツがめまぐるしく変更される場合
クロールの速度(クロールレート)
クロールの速度が速すぎればサーバーに負荷をかけ、他の訪問者のウェブサイト表示が遅くなってしまいます。
その為、GoogleBotは他のウェブサイト利用者の利便性を損ねないように、クロールレートの最大値を制限しているようです。クロールレートとは次のように説明されています。
“単純化を恐れず言えば、クロールレートは、Googlebot でサイトのクロール時に使用する同時並行接続の数、および次の取得までに必要な待ち時間を表します。”
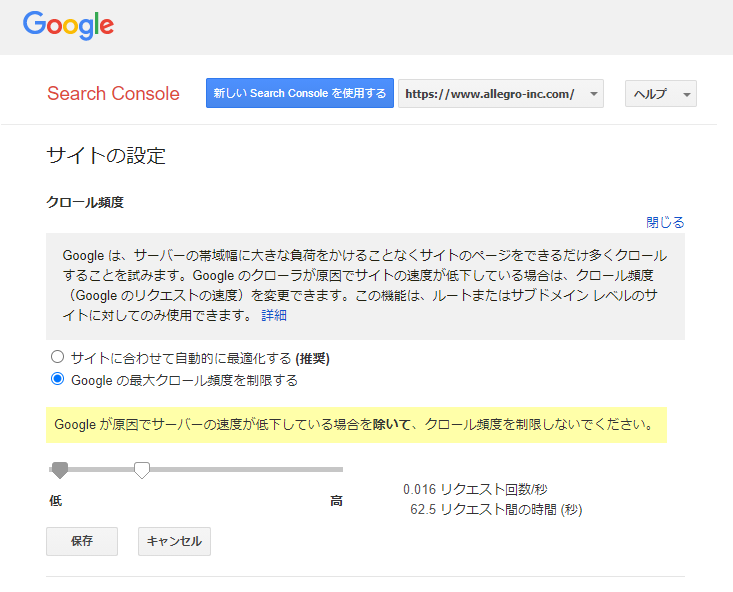
クロールレートはSearch Consoleの特殊なページで設定を行う事ができます。
なお、ページコンテンツの文章量はクロールレートや頻度、インデックスの決定に影響しないようです。人気のあるコンテンツはリンクなどを経由してクロールされやすくなって、インデックスにも良い影響を与えるそうです。
The length of the content doesn’t influence how often we crawl and whether we index it. It also doesn’t contribute to the crawl rate of a URL pattern.
Gary氏の発言 English Google SEO office-hours from November 2022
クロールレートを抑えるために403や404を使用しているサイトやCDNが増えているようですが、これは適切な方法ではないようです。クライアントに対してエラーを伝えるコードであって、サーバーの負荷を伝えるには不適切なようです。
詳しくは「クロール頻度の抑制に 403 または 404 を使用しないでください」をご覧ください。
クロールの優先度
規模の大きなサイトが素早くクロールされがちに見える点について、John Muller氏のコメントが興味深いです。
クロールの優先度はサイズというよりも、ページで提供される価値の重要性や追加される独自性に基づいて判断されるだろうと発言しています。
クロールの必要性(クロールディマンド)
人気の高いURL(おそらく被リンク)やURLの鮮度によってクロールを決定するようです。人気があるURLはクロールの頻度が高くなり、Googleのインデックスした内容が古くならないように定期的にクロールします。
Gary Illyes氏の発言では、より頻繁にクロールが必要な範囲をサイト全体から推測しているようです。例えば、ブログを扱うサブディレクトリがあり、そのブログが人気で重要であることを示すシグナルを見つけた場合、Googleはより頻繁にクロールする可能性があります。
ページの更新頻度が単純に重要ということではなく、品質も重要となります。例えば、人気のサブディレクトリがあれば、人々はそれについて会話し、リンクを追加します。これが人気を判定するシグナルとなっているかもしれません。
ちなみにSearch Consoleの登録の有無がクロール頻度に影響することはないと、Jouhn Muller氏がコメントしています。
クロール時の1ページあたりサイズ上限
以前は1ページあたり10MBと言われていましたが、現在では数百MBに増えています。
サーバーレスポンスが早い程多くのページをクロールする
サーバーレスポンスを含めてページ表示速度を改善していく事は、ユーザーの利便性だけでなく、Googlebotの処理速度向上にも繋がります。
John Mueller氏の発言では、レスポンスが早ければ、クロール速度も上がり、より多くのページをクロールします。
クロールバジェットのコントロール
noindexによるクロールバジェットの節約
クロールバジェットをコントロールする方法としては適切ではないものの、インデックスする必要のないページに対して長期的に使用することで間接的にクロール バジェットを解放することにはなるようです。
Any URL that is crawled affects crawl budget, and Google has to crawl the page in order to find the
noindexrule.However,
Large site owner’s guide to managing your crawl budgetnoindexis there to help you keep things out of the index. If you want to ensure that those pages don’t end up in Google’s index, continue usingnoindexand don’t worry about crawl budget. It’s also important to note that if you remove URLs from Google’s index withnoindexor otherwise, Googlebot can focus on other URLs on your site, which meansnoindexcan indirectly free up some crawl budget for your site in the long run.
ソフト404はクロールバジェットの浪費につながる
GoogleのGary Illyes氏の発言によれば、404や410はクロールバジェットの浪費には繋がらないようです。単純にステータスコードだけを取得するだけのようです。一方でソフト404はインデックスにも含まれず、クロールバジェットの浪費にもつながります。
CDN上の画像については異なるクロールバジェットが割り当てられる
外部CDN上で画像を提供するウェブサイトの場合は、CDNのドメインに対して、あなたのウェブサイトのドメインとは別のクロールバジェットが割り当てられます。ただしCDNがウェブサイトのドメインと同じサーバーで、大きな変化が無い場合は一つにまとめたクロールバジェットとなるようです。
Just to be clearer, if your images are on yoursite. somecdn .com, and your content on www. yoursite .com, we would try to track the server capacity separately for them. (exception: if it’s the same server, that doesn’t change much, so we might fold it together then)
— 🐄 John 🐄 (@JohnMu) November 22, 2021
サイトに割り当てられるクロールバジェット
サイト内のページや画像の他、以下のような項目もクロールバジェットの対象となるようです。
- AMPやhreflangのような代替URL
- CSS、JavaScript、AJAX(XHR)コールといった埋め込みコンテンツ
- 長いリダイレクトの連鎖もクロールに悪影響
GoogleBotになるべく効率よくクロールしてもらう為には、XMLサイトマップを作成してGoogleに登録したり、ウェブサイト内の階層構造を見直すといった方法もあります。
Cache-Control ヘッダはクロールやインデックスに影響を与えない
Cache-Contorolはブラウザに対して適用されます。Googleのクロールやインデックスでは適用されません。
Cache control headers don’t apply to Google’s crawling & indexing, they’re for browsers. At most, they might be used in rendering for embedded content.
John Mueller氏の発言
x-ratelimit-limit HTTPヘッダの記述は参照しない
John Mueller氏のコメントによると、Googleは”x-ratelimit-limit” HTTPヘッダは認識しないようです。代わりにHTTP429と503でスローダウンを要求していることをドキュメントで示しています。
Googlebotのプロトコル選択の概要
Googleの更新によれば、Googlebotは以下のようにプロトコルを選択します:
「GoogleのクローラーとフェッチャーはHTTP/1.1およびHTTP/2をサポートしています。クローラーは、最も効率的なクロールパフォーマンスを提供するプロトコルバージョンを使用し、過去のクロール統計に基づいてクロールセッション間でプロトコルを切り替える場合があります。」
デフォルトではHTTP/1.1が使用されますが、HTTP/2を使用することで、サイトおよびGooglebotのコンピューティングリソース(CPU、RAMなど)を節約できる可能性があります。ただし、HTTP/2を使用しても、検索ランキングに直接的な影響はありません。
サイト運営者への影響と対応策
HTTP/2の利点と制限
- 利点:HTTP/2は、マルチプレクシングやヘッダ圧縮などの機能により、効率的なデータ転送を可能にし、クロールパフォーマンスの向上が期待されます。
- 制限:HTTP/2を使用しても、Google検索におけるランキング向上などの直接的なSEO効果はありません。
HTTP/2クロールのオプトアウト方法
HTTP/2によるクロールを避けたい場合、以下の方法があります:
- HTTP 421ステータスコードの使用:サーバーがHTTP/2でのアクセスに対してHTTP 421ステータスコードを返すよう設定することで、GooglebotはHTTP/1.1にフォールバックします。
- Googleのクロールチームへの連絡:上記の設定が難しい場合、一時的な措置としてGoogleのクロールチームに連絡することも可能です。
背景と今後の展望
Googleは2020年11月から一部のURLでHTTP/2によるクロールを開始し、1年後にはウェブ全体の約半数をHTTP/2でクロールしていました。今回のドキュメント更新は、Googlebotが最適なクロールパフォーマンスを実現するために、プロトコルを動的に選択する方針を明確にしたものです。
Googleボットによるページ内コンテンツの認識
Googleボットがページの情報を取得する際に、ページをChromeブラウザでレンダリング(描画)します。縦に長いページであってもきちんと認識できるように設計されています。
Googleボットのビューポートサイズ
CSSや画像なども含めてレンダリングできるように、9000pxの高さのビューポートを使用しているようです。
Googlebot renders with a very tall viewport, which skews some CSS (often images). Try in Chrome dev-tools, eg 9000px high viewport.
— 🍌 John 🍌 (@JohnMu) November 1, 2017
Intersection ObserverでGoogleボットに認識してもらう
ただし、Googleボットは、何もしなければスクロールやクリックせずにページの情報を取得する為、一部がLazy load(遅延読み込み)で表示されるコンテンツの場合は、その部分を認識できない可能性があります。Intersection Observerを設定する事で、Googleボットはそれを使用してコンテンツを見つける事ができます。
Intersection Observerについての詳細は以下のページをご覧ください。
Googleボットが認識できる最大HTMLファイルサイズ
Googleの公式ドキュメントによると、
GooglebotはHTMLファイルの最初の約15MBまでを処理する
と明記されています。
✔ 15MBを超えるとどうなる?
- 15MB以降のHTML部分はインデックス対象外になる可能性
- 後半に配置された重要テキストが評価されない可能性
- 後方に置かれた構造化データが読み取られない可能性
つまり、「ユーザーには見えているがGoogleは読んでいない」状態が発生する可能性があります。
ちなみにPDFファイルは64MB、その他サポート対象ファイルは2MBの制限があります。
ファイルサイズの上限に達した場合、Googlebotは取得を停止し、既にダウンロード済みのファイル部分のみをインデックス登録の検討対象として送信します。ファイルサイズ制限は、圧縮前のデータに対して適用されます。その他のGoogleクローラー(例:Googlebot VideoやGooglebot Image)は、異なる制限が適用される場合があります。
Googleは文字通りリンクをクリックしてクロールしているわけではない
Googleはリンクを抽出し、抽出したリンクURLをデータベースに収集し、後で確認します。リアルタイムにリンクをクリックして巡回しているわけではありません。
⚙️ Googleが明かす:タブ式コンテンツは「見える」?「クローラブル」?
🔍 タブコンテンツ、Googleはどう見ている?
1. タブの「クリック」はしないが…
- GoogleのJohn Mueller氏によると、Googlebotは通常、JavaScriptで切り替えるタブに「クリック」はしません。
- しかし、タブの内容が初回ロード時にDOMに存在していれば、インデックス対象になり得ます。
2. DOMに読み込まれればOK
- 「ページ読み込み時に全タブ内容を含めておく」構成なら、その内容はGoogleに“見えている”状態になります。
- 一方、「onclickイベントで初めて読み込む」構成では、Googlebotがそのコンテンツを認識する可能性が低くなります。
🧰 インデックスされているか確認するには?
- Search Consoleの「URL検査ツール」内にある「Inspect URL」機能を使うと、Googleが「どんなHTML/DOM構造を見ているか」が確認できます。
- ここから、タブ内コンテンツが実際に読み込まれているか確かめられます。
⚠️ SEO/UXの最適な実装ポイント
- ユーザー視点のコンテンツ設計を忘れずに
- タブを開かないと重要情報が見えない状態は、訪問者がすぐ離れるきっかけになります。離脱リスクを軽視できません。
- 別URLで提供する必要がある場合のみリンクを活用
- 他ページとして扱いたいなら
<a>要素にして認識しやすくするのが理想です。そうでなければUXを難しくせず、シンプル構成に。
- 他ページとして扱いたいなら
✅ まとめ
- タブ式コンテンツでも、初回ロードでDOMに含めればGoogleは認識できる可能性あり!
- ただし、UXが重要:コンテンツがすぐ見えないレイアウトは検索で評価されてもユーザーには認識されにくくなる可能性大。
- 確認ツールを活用しつつ、ユーザーに優しいタブ設計を心がけましょう。
タブ型ナビゲーションを採用する際は、「技術的にクロールできるからOK」として終わりではなく、検索とユーザー体験(UX)の両立を視野に入れることが、質の高いウェブサイト構築のポイントになります。
Googleがサーバーにアクセスできない場合の処理
以下の手順は、サーバーが長期間停止、またはアクセスできなかった場合のGoogleの処理を示しています。短期間のサーバーダウン程度であれば、検索順位に大きな影響を与える事はないようです。
- ネットワークやDNSが原因でウェブサイトにアクセスできない場合、5xx HTTP サーバーエラーとしてみなします。
- URLは同様にインデックスされたままになり、エラー以前と同様にSERPに掲載されます。つまり、短期間では特に大きな変化はありませんが、これは一時的な対応にすぎません。
- 1~2日以上の間、継続的にエラーが発生している場合 は、インデックスからそれらのURLを除外し始めます。サーバー停止によってGoogle検索のインデックスからページが削除されまでに数日かかります。
- 発生時には直接的な順位変動はありません。Googleはそのサイトを低品質や類似だとはみなしませんが、インデックスから削除されていればどのみちSERPには掲載されません。その為、ウェブサイトが酷い評価で扱われていると感じてしまうかもしれません。
- ウェブサイトが復旧すると、通常ならばGoogleがインデックスから削除していたURLも再度正常にクロールされればすぐに元に戻ります。
- Googleが正常に読み込める事を検知した場合には、Googleボットのクロール処理はスピードアップします。
If you’re curious about what happens in Google Search with an outage like Facebook recently had, it’s generally a 2-part reaction: when we can’t reach a site for network / DNS reasons, we see it like a 5xx HTTP server error. This means we reduce crawling: https://t.co/V7CjrVq3yJ
— 🐄 John 🐄 (@JohnMu) October 5, 2021
Googleがクロール中止を判断する2つのシグナル
Googleはあウェブサイトのクロールを停止するかどうか判断する為に、リンク否認ツールや、robots.txt、nofollowなどの多くのシグナルを使用しています。
その他にGoogleにとって2つの重要なシグナルがあります。
接続時間
Googleは、サーバーへの接続時間を見ています。
接続時間が長ければ長いほど、Googleはスローダウンしたり、ウェブサイトのクロールを停止するようになります。
Googleは、あなたのウェブサーバーに負荷をかけたくないので、接続時間はクロール要素の一つとして使用しています。
HTTPステータスコード
Googleは、サーバーステータスコードが5xxの範囲である場合、クロールをストップしたりスローダウンしたりする事があります。
5xx範囲のステータスコードはサーバーレスポンスに問題がある事を意味します。
これらのコードをGoogleが見た場合、サーバーに更なる問題を発生させないようにクロールを中止します。
どちらのケースであっても、GoogleBotはその後に再びクロールしにきますが、これらのシグナルを発見した場合はクロールを継続しません。
ステータスコードが5xxの範囲の場合に、クローラーがスローダウンしてしまうという事はJohn Mueller氏も同様の発言をしています。
ステータスコードによってGoogleがどのように判断するかについては以下のページでまとめていますので、興味があるようでしたらご覧ください。

自身で管理するウェブサイトの全ページのステータスコードを確認したり、スピード改善に必要な項目をチェックしたり、その他SEOで問題となる箇所をチェックする場合には、SE Rankingの「サイトSEO検査」機能が便利です。
この機能では、実際にツールがウェブサイト内のページを巡回し、問題点を検知してレポートしてくれます。
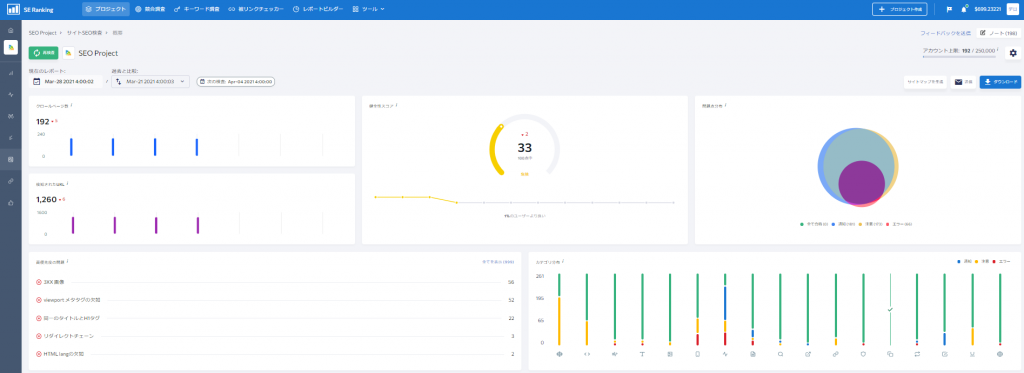
サイトSEO検査機能を含め、多くの機能を2週間無料で利用可能なトライアルアカウントを作成して、ウェブサイトの順位や、問題点、被リンクの状況をチェックする事ができます。興味がございましたらお試しください。