特定のページに対してメタタグでnoindex、nofollow、noarchiveの記述を加えることで検索エンジンのクローラに対して、ページの処理を指示する事ができます。
2024年10月7日、Googleは「noarchive」メタタグのサポートを正式に終了しました。このタグは、検索結果にキャッシュリンクを表示しないようGoogleに指示するものでしたが、Googleがキャッシュ機能自体を廃止したことにより、もはや必要なくなったためです
一般的には検索結果に出す必要の無い、または出したくないページがある場合にnoindexタグを記述しますが、もし検索結果に自分のページを表示させたいにも関わらず、noindexやnofollowが記述されている場合は修正したほうが良いでしょう。
各タグの効果について説明します。
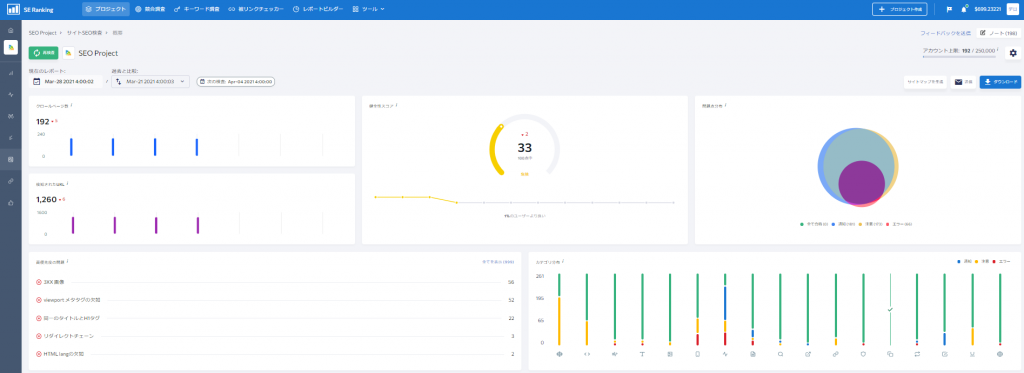
当ブログでも活用しているSE Rankingの「サイトSEO検査」機能なら、ウェブサイトの内のページを巡回して、noindexやrobots.txt設定のミスを検知します。
それ以外にもキーワード調査や順位調査、被リンク分析、競合調査などSEOに役立つ強力な機能や、SNS管理、ユーザー管理、マーケティングプラン機能など豊富な機能とプランの費用を柔軟に選択できるといった特長を持ちます。
2週間の無料トライアルが利用できますので、興味をお持ちなら是非試してみてください。
クローラーを制御する記述(メタ)とは
headタグ内のメタタグに、ロボットに関する制御を記述する際に、noindex、noarchive noneなどがあり、これらの指示をディレクティブと呼びます。具体的には下記の通りです。
クローラーを制御する記述の具体例
- noindex
-
noindexはインデックスの拒否を指示します。
<meta name=”robots” content=”noindex”>
- noarchive
-
noarchiveは、検索エンジンデータベースへの保存の拒否を指示します。
<meta name=”robots” content=”noarchive”>
検索エンジンデータベースへの保存の拒否は、簡単に言えば検索結果のキャッシュに表示させないという意味になります。
用途としては、比較サイトやECサイトなど頻繁に情報が変更されるページにnoarchiveを記述することはあり得ます。何らかの拍子でキャッシュを閲覧し、古い価格情報に惑わされるユーザーもいるかもしれないからです。ただし、Googleについてはすでにキャッシュリンクは廃止されていますので、その他のBingなどの検索エンジンを考慮する記述として使用することになるでしょう。
ちなみにnoarchiveを記述する事で順位に何らかの影響がでる可能性を心配されるかたもいるでしょう。
この点についてはGoogleのJohn Mueller氏がきっぱりと否定しています。https://twitter.com/JohnMu/status/902626076874158080?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E902626076874158080%7Ctwgr%5E%7Ctwcon%5Es1_&ref_url=https%3A%2F%2Fwww.allegro-inc.com%2Fseo%2Fnoindex-nofollow-noarchive - none
-
noneは、インデックスとリンク先へのクロールの両方を拒否を指示します。
<meta name=”robots” content=”none”>
- nofollow
-
nofollowは、ページ上の配置されているリンクを辿らないようにクローラーへヒントを伝えます。
※2019年9月から強制力のあるディレクティブから弱い意味のヒントへとルールが変更となっています。<meta name=”robots” content=”nofollow”>
この他、検索結果にスニペットを表示させないnosnippetや、
そのページの画像をインデックスさせないnoimageindex、
メディアパブリッシャーが自身のコンテンツ自体はインデックスさせたくないものの、第三者ページで埋め込みに使用された際にはそのコンテンツをインデックスさせたい場合にnoindexとセットで使用するindexifembedded、
指定した日以降に検索結果に表示されなくなるunavailable_after: [RFC-850 date/time]などのディレクティブがあります。
X-Robots-Tag HTTP ヘッダー
robotsメタタグを使用しない場合の選択肢として、特定のURLのHTTPレスポンスヘッダーの要素として、X-Robots-Tagが使用できます。
X-Robots-Tag: noindexはインデックスの拒否を指示します。
X-Robots-Tag: noindex
実際に設定する場合には、「.htaccess」か「httpd.conf」というファイルを直接編集するケースが多いかもしれません。
※ご利用のサーバーによって異なります。
Googleの解説はファイル単位での設定例が記載されていました。
<Files ~ “\.pdf$”>
Header set X-Robots-Tag “noindex, nofollow”
</Files>
URL単位で指定する場合には、httpd.confで別の方法で設定しなければならないようです。
誤って記述してしまうと?
当然ですが、表示させたいページまで検索結果から除外されてしまいます。
WordPressで新規サイト制作時に、検索エンジンから制作途中のページがインデックスされてしまう事を防ぐ為、noindexを指定する事があります。そしてnoindexの設定のまま、設定を切り替える事を忘れて公開してしまう場合があります。
これでは折角ウェブサイトを公開しても検索結果に表示されません。
noindexとrobots.txtでよくある誤った設定
既存のインデックスされているページを検索エンジンに表示させないようにメタでnoindexを設定し、robots.txtでそのページへのクロールもブロックしてしまうと、いつまでたっても検索結果に表示されたままになってしまうようです。
@suzukik あるページが既にインデックスされている場合、それをインデックスされないようにするために robots.txt でクロールをブロックしてしまい、結果として noindex が検索エンジンに認識されないままになってしまう、というのはしばしば見られる誤りなので、
— Kazushi Nagayama 🗿 長山一石 (@KazushiNagayama) October 15, 2015
robots.txtの設定とnoindexの設定はクローラーを制御するという意味では似たような部分がありますが、正しく理解した上で使用しなければなりません。
robots.txt同様に、canonical指定先のページがnoindexになっている状況などもGoogleが混乱する可能性がある為避けた方が良いでしょう。
Googleは制限が強い方のクロールコマンドを使用する
Googleのボットは、クロールコマンドの記述に関し矛盾する状況に直面した場合には、より制限の強い方のコマンドを使用するようです。
例えば次のような具体例が示されています。
- noindexとindexの両方を同じページに記述した場合はどのように処理される?
-
Googleはnoindexとして処理します。
- オリジナルのHTML上でnofollowを記述、JavaScriptでその記述を削除している場合はどのように処理される?
-
Googleはnofollowとして処理します。
- ロボットメタタグは記述無し、JavaScriptでnoindexの記述を追加している場合はどう処理される?
-
Googleはnoindexとして処理する
- noindex,followを記述している場合はどのように処理される?
-
noindex,followの記述は、最初はnoindexとして処理されますが、一定期間経過するとnoindex,nofollowとみなされるようです。
noindexを一定期間Googleが見続けることで、当然Googleのインデックスからそのページは除外されます。
ページを辿らなくなれば、リンクも辿りませんのでnofollowと同じ結果となってしまいます。 - iframeでnoindexメタタグが指定されているコンテンツを埋め込んだページはnoindexとして処理される?
-
Twitter上でのJohn Muller氏のコメントによると、そのような事は無いようです。心配であれば、Search ConsoleのURL検査ツールを使って正常にクロール、インデックス出来るかどうかをテストしておくと良いでしょう。
ツールで noindex / nofollow が記述の有無をチェック
SEO管理プラットフォームのSE Rankingでは、ウェブサイト内の全てのページを巡回して、noindeやnofollowが指定されているページを一括で抽出してくれます。noindexやnofollowを誤って指定しまうと、検索集客に悪影響を及ぼす事もある為、必ずチェックするようにしましょう。
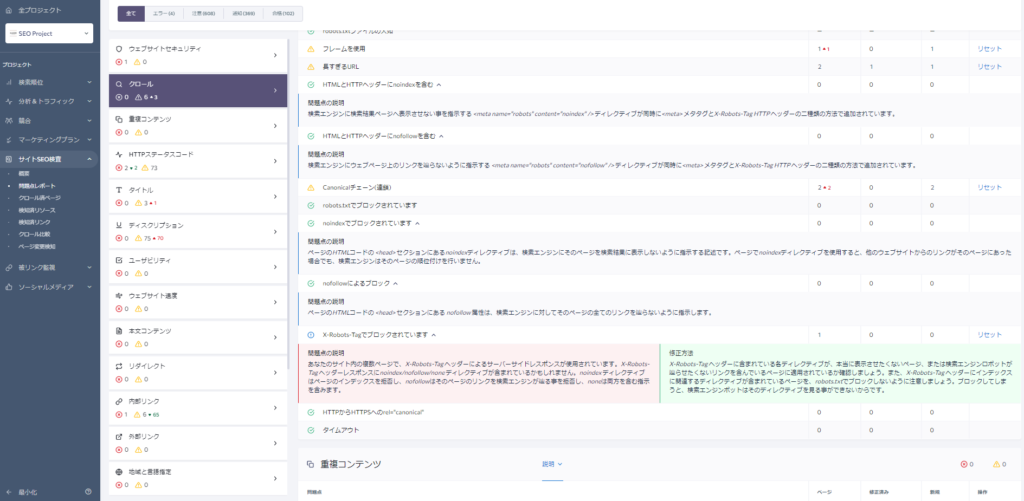
チェック手順
SE Rankingの無料トライアルアカウント作成ページで自身のアカウントを作成しましょう。クレジットカード登録不要で2週間無料で利用できます。
以下の手順に沿って、チェック対象のウェブサイトに関するプロジェクトを作成しましょう。プロジェクトを作成してしばらくすると、サイトSEO検査が完了します。
左側メニューの「サイトSEO検査」のサブセクションの「問題点レポート」クリックして確認しましょう。
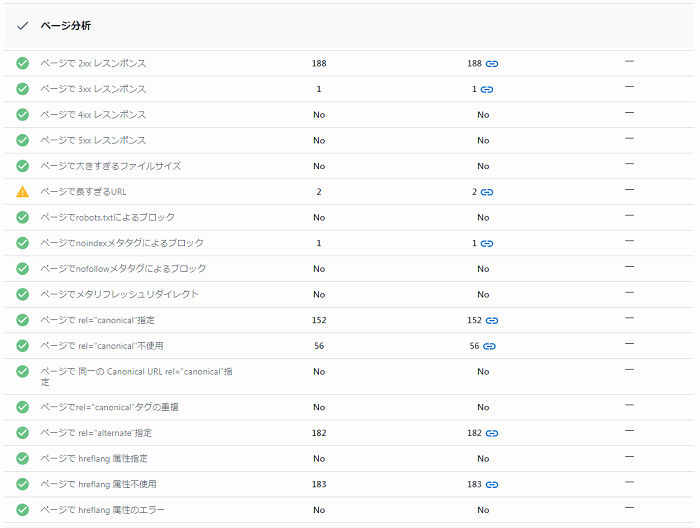
「クロール」セクションをクリックし、セクション内に問題点が無いか確認しましょう。問題点の項目をクリックすると改善方法のガイドが表示され、ページ列の数値をクリックすると問題が発生しているページも確認する事ができます。
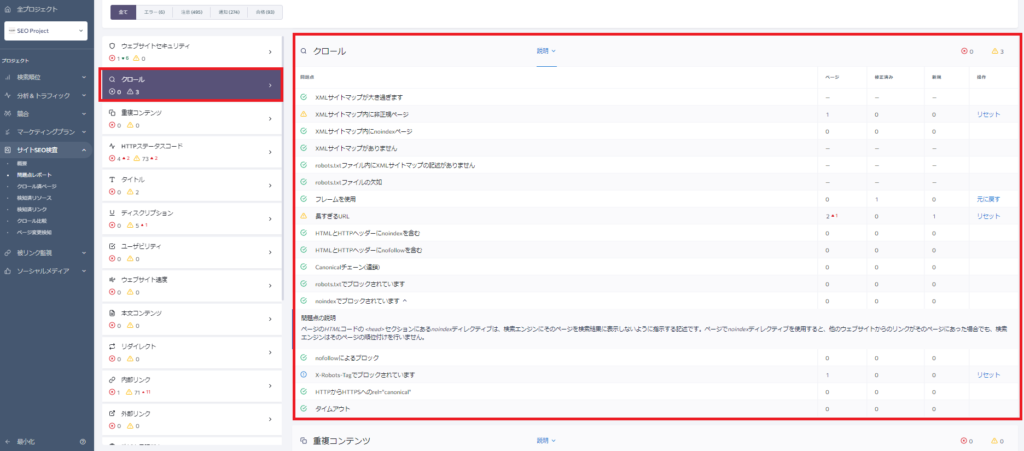
Robots メタタグとX-Robots-Tagに関するチェック内容
- HTMLとHTTPヘッダーにnoindexを含む
-
検索エンジンに検索結果ページへ表示させない事を指示するディレクティブが同時に メタタグとX-Robots-Tag HTTP ヘッダーの二種類の方法で追加されている状態です。
- HTMLとHTTPヘッダーにnofollowを含む
-
検索エンジンにウェブページ上のリンクを辿らないように指示するディレクティブが同時に メタタグとX-Robots-Tag HTTP ヘッダーの二種類の方法で追加されている状態です
- noindexでブロックされています
-
ページのHTMLコードの セクションにあるnoindexディレクティブは、検索エンジンにそのページを検索結果に表示しないように指示する記述です。ページでnoindexディレクティブを使用すると、他のウェブサイトからのリンクがそのページにあった場合でも、検索エンジンはそのページの順位付けを行いません。
- nofollowによるブロック
-
ページのHTMLコードの <head> セクションにある nofollow 属性は、検索エンジンに対してそのページの全てのリンクを辿らないように指示します。
- X-Robots-Tagでブロックされています
-
X-Robots-Tag ヘッダーによるサーバーサイドレスポンスが使用されています。X-Robots-Tag ヘッダーレスポンスにnoindex/nofollow/none ディレクティブが含まれているかもしれません。noindex ディレクティブはページのインデックスを拒否し、nofollowはそのページのリンクを検索エンジンが辿る事を拒否し、noneは両方を含む指示を含みます。
SE Rankingの「サイトSEO検査」はウェブサイト内の全てのページを巡回し、noindexやnofollow以外にも、SEOに大きな影響を与える要素を一括でチェックしてアドバイスを表示します。
無料で2週間利用できるトライアル版が利用できるので、一度ウェブサイトに大きな問題点が無いかチェックしてみてはいかがでしょうか。
オプトアウトツールでGoogle検索結果からウェブサイト全ページを表示させない方法
ここでご紹介する方法は、全てのページをGoogle検索結果に表示させない方法です。
使用する場合は、よく理解した上で活用しましょう。
Googleは検索結果から管理するサイトを表示させないように設定する事ができる、オプトアウトツールを提供しています。
オプトアウトツールとは?
Googleの検索結果から、サイトのコンテンツを非表示にする方法は複数ありますが、今回のオプトアウトツールは、Googleがクロールし、Google ShoppingやAdvisor、Flights、Hotels、Google+ローカルサーチに表示されるコンテンツを非表示するものです。
Search Consoleで、お持ちのサイトをこれらのGoogle関連の検索結果から30日以内に取り除く事ができるようです。
設定はドメインレベルで設定可能で、トップドメインのみでサブドメインでは設定できないようです。また、一度オプトアウトすると、再度検索結果にオプトインさせる為に最長3ヶ月程度かかる場合もあるようです。